


Voice Accent is an academic project developed from postgraduate research that employs voice interfaces (VUI), artificial intelligence and machine learning to create an interface capable of switching between two similar languages or regionalisms without the need for additional configurations via a voice system.


01 / SUMMARY
02 / Process
03 / Undestanding the problem
04 / Speak and accent
05 / Phoneme translations
06 / Decision tree
07 / Learnings
02 / PROCESS
empathize
>
>
>
research
ideate
prototype
EMPATHIZE
03 / UNDERSTANDING THE PROBLEM
The Voice Accent project was born from the observation that the current voice command virtual assistants on the market don't understand the differences between different but similar languages, or even between regionalisms. An example of this is that, when configured in Portuguese, these assistants can easily find results in English, but get confused if we search for a topic in Spanish. Given this context, is it possible to create a voice experience that doesn't require a graphical interface for adjustments? How does this behavior affect the use of voice devices by people with accents, especially foreigners learning a new language? Could artificial intelligence help in this process?
Voice interfaces (VUI) are part of the group of natural interfaces, i.e. interfaces that work so discreetly and naturally that we don't even realize they are there. Speech is natural for human beings and, as long as they don't have cognitive or hearing impairments and speak a common language, it is also our main means of communication.
In 2023, a survey by the Getúlio Vargas Foundation (FGV) revealed that 67% of people in Brazil use voice interfaces in their daily lives. This figure certainly includes foreigners and people with different accents. However, these interfaces are generally programmed by people from the southeast region of Brazil, especially São Paulo, which ends up generating a standard accent. As a result, people who speak differently report difficulties in using this type of technology, which leads to frustration and giving up.
04 / SPEAK AND ACCENT
The Interaction Design Foundation defines voice interfaces as systems that enable user interaction through spoken commands. Examples of such interfaces include virtual assistants powered by artificial intelligence. This study aims to explore the effects on bilingual individuals residing in countries where the language differs from their native language, particularly in their interactions with AI-based virtual voice assistants, given that accents can affect the user experience.
The niche used for the target audience is made up mainly of foreigners from Hispanic countries who live in Brazil and are bilingual between Brazilian Portuguese and Latin Spanish.
Voice interfaces and discrimination: how the way we speak affects the experience
It's important to combat linguistic prejudice, which is nothing more than the tendency to ignore a way of speaking. To do this, I had to understand the difference between the cultured norm and the standard norm of languages: the cultured norm is linked to the everyday use of the language, varying according to the level of education and origin of the speaker. The standard norm, on the other hand, is the orthographic-grammatical agreement of the language itself. Linguistic variation occurs due to the influence of culture and social context, which is why the Portuguese spoken in Brazil is different from the Portuguese spoken in Portugal, for example.
Languages commonly exhibit linguistic variations, including accents and mannerisms, which can vary based on the region, origin, or social class of the speakers. This complexity is further amplified when considering different languages that share the same origin, like the Latin languages.
This linguistics primer contextualizes the use of voice interfaces. The reason virtual assistants struggle with certain speech patterns is rooted in the databases used to train their AI. These databases are thought to contain biases that lead to statistical filters in the AI's performance, resulting from "sanitized and homogeneous" data that skews machine learning. While not intentional on the part of designers and developers, the choices made during the programming of voice interfaces inadvertently shape their behavior. Employing neural networks to discern language parameters is one method to lessen this issue, yet it's impossible to completely remove the bias.
Spanish-Portuguese interfaces


Given the context mentioned in the previous paragraphs, I focused the product on the Spanish-Portuguese niche. In the relationships that occur between these languages, it is very common to encounter misinterpretations for both Portuguese and Spanish speakers, due to the proximity between the two languages. Obviously, this is also reflected in voice interfaces. To prove this hypothesis, I launched an online survey on social media with people from Spanish-speaking countries, living in Brazil and fluent in Portuguese, who also have bilingual families and use voice interfaces configured in Portuguese in their daily lives. The survey revealed that:
IDEATE
05 / PHONEME TRANSLATIONS: A CASE STUDY USING ARTIFICIAL INTELLIGENCE AND NEURAL NETWORKS
As an idea to reduce the margin of error of virtual assistants for bilingual users of close languages (or even different accents within the same language), a study published by Cornell University in 2019 proposed modifying the artificial intelligence of VUIs so that they can identify phonemes instead of complete words and learn linguistic variations through neural networks.
Neural networks are computer systems that reflect the behavior of the human brain, allowing programs to recognize patterns and solve problems through artificial intelligence. They rely on training data that is used for machine learning and to improve the software's accuracy over time.
A common method of creating virtual assistants is to rely on a large lexicon containing word pronunciations. However, this lexicon is created manually by developers and designers, which limits the variety of vocabulary. A possible solution to this problem is to allow the software to learn phonemes and automatically expand the databases without the need for manual updating.
Virtual assistants were initially developed with an extensive English lexicon, which was then expanded to include other languages. The majority of phonemes, approximately 90.8%, are unique to their respective language groups, yet they have many variations and representations. These are utilized in the development of bilingual voice interfaces to prevent artificial intelligences from making errors with similar words across different languages. By training the software with cross-references and creating databases capable of processing phoneme sequences of any length, the system can identify the target language by comparing the sounds in its databases. This eliminates the need for users to manually configure their virtual assistant, enabling a bilingual interaction that is smooth and more akin to human conversation.
To arrive at the solutions proposed in the next section, the double diamond technique was used.
The first step was to identify the problem to be solved: "how accent influences interaction with a voice interface", identify the target audience and understand their needs. The insights gained showed that the artificial intelligence of virtual assistants influences interaction.
The market should concentrate on the machine learning algorithms and their processing of sounds and words. My analysis of techniques and solutions for the identified issue led me to conclude that the inadequate interaction with voice interfaces stems not just from design flaws, but also from development and engineering challenges.
Ultimately, the outcome will be a decision tree along with recommendations for creating an optimal voice interface, designed to seamlessly transition between various similar languages.
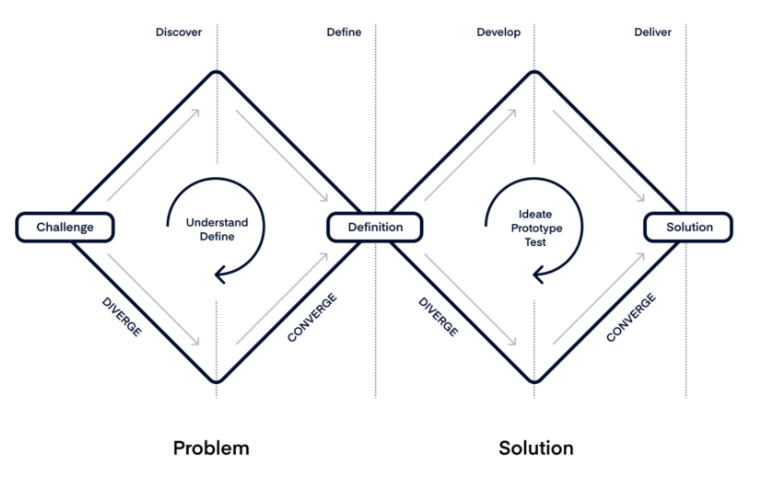
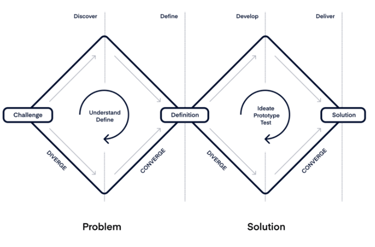
Double-diamond. Credits: Product Board.


Raul Gonzáles
Age: 25 - education: university degree
"I must repeat my words. The intercom simply doesn't understand the accent as it's set up in Portuguese."
Bio: A Hispanic living in Brazil for a short time, he uses virtual voice assistants configured in Portuguese to become more familiar with Portuguese. He uses his work time to practice conversation with his Brazilian colleagues. Frustration: He still hasn't mastered Portuguese very well. He needs to improve his fluency in Portuguese. Digitalized user, used to technology.


Mariela Aguirre
Age: 40 - education: high school
"It wasn't understood because I have a Spanish accent, so, it doesn't finish the task indicated."
Bio: Hispanic living in Brazil for a few years, but still has a lot of difficulty with nasalized sounds typical of the Portuguese language. Married to a Brazilian and the mother of a son, she lives in a bilingual Spanish-Portuguese family because she wants the child to grow up involved in the cultures of both parents. Frustration: She has difficulty with typical Portuguese phonemes that don't exist in Spanish. Needs: to improve her fluency in Portuguese A user who uses technology for small everyday activities. She is not interested in the latest innovations on the market, but in products that can help her solve her problems.
SOLUTION
06 / DECISION TREE
Voice interfaces are often prototyped with flowcharts and decision trees, which are used interchangeably in interface design. A decision tree maps out potential outcomes of an interaction based on various choices. Typically, they begin at a single node and branch out into multiple pathways.
When initiating an interaction with a voice interface, it typically begins in an open-ended manner, allowing the user to speak freely. For instance, self-service chats often commence with the prompt, "what can I do for you?" to which users respond in their own words. The interface then interprets the scenarios using keywords as indicators to steer the conversation.
The keywords in the design of this system include Portuguese-Spanish false cognates, phonemes composed of LL, CH, J, RR, R, Ñ, NH and X and nasalized sounds represented by the accent ~.
Next, a simplified decision tree is presented to illustrate the design of a bilingual voice interface in Portuguese and Spanish, considering an artificial intelligence method that not only understands whole words, but also phonemes.

RESEARCH
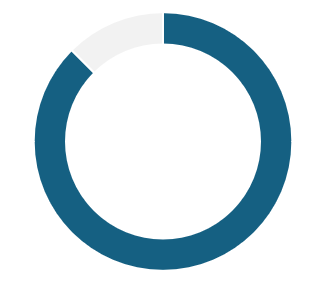
62.5% do not use any
voice interface
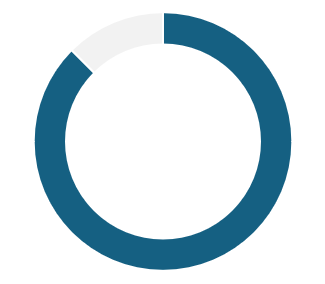
87.5% live in
bilingual families
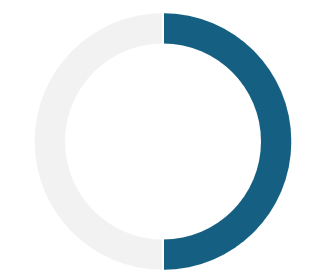
50% report having had difficulty using voice interfaces configured in Portuguese
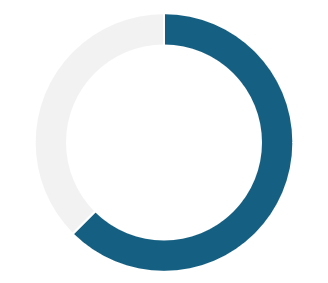
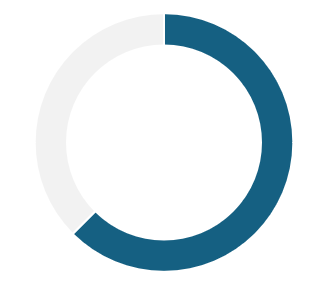
Users with Hispanic accents often report that they must repeat commands to virtual assistants set to Portuguese, as their words or the context of their speech are not understood, leading to unexpected responses. This frustrating experience has led many to abandon using these interfaces.
I also researched how the artificial intelligence of voice interfaces learns new words. Currently, most have databases that are fed with complete words, which makes it difficult for the machine to understand because it waits for certain sequences of sounds.
When the problem of accents in voice interfaces is tackled by exploiting machine learning through neural networks and phonemes, the machines become more assertive.
Generative grammar is a theory that says that grammar is based on rules that tell you how to make sentences in a language.
Deep residual networks are a type of specialized neural network that helps artificial intelligence deal with complex machine learning models.
Attention mechanisms are a way of representing vectors in machine learning models, where it is possible to read each part of the information vector independently.






As mentioned above, the target audience for this project is foreigners, especially Hispanics, who have difficulty using voice interfaces configured in Portuguese. Based on the study of this target audience, the following protopersonas were created:
Simplified decision tree. Click to expand the image.
As mentioned throughout this paper, designing a voice interface capable of understanding bilingual users outside their native languages is a challenge for both design and technology. The user experience designer's job is always to think about the best experience and problem-solving, but we also have to deal with technical/technological limitations. In the case study of this project, the limitation is linked to the artificial intelligence methods currently used in virtual assistants. Currently, these assistants have no memory and cannot understand the context of a speech, resulting in a forced end to the interaction when they do not understand the commands and generating frustration in the user. It is hoped that in the near future, artificial intelligence and phoneme-based machine learning methods will be improved and become more popular, resulting in more precise interfaces that offer more freedom for design decisions.
RESULTS
07 / LEARNINGS
Virtual assistants based on voice commands and artificial intelligence are types of voice interfaces that are becoming increasingly popular with users. These interfaces were born in English and have gradually been translated into many other languages. However, current generations are not yet capable of acting in bilingual mode or even monolingual mode when the user is not a native speaker of the configured language or uses many regionalisms.
Therefore, for a voice interface and a virtual assistant to become more accessible to different types of speech, it is necessary for designers to study the different ways users speak, while developers take care to use cutting-edge technologies capable of learning words by phonemes.
It's a great market opportunity to design interfaces like this, as many users complain about not being served properly, to the point of abandoning the use of virtual voice assistants. A designer must always be aware of users' needs and problems and design solutions that appeal to their target audience and bring good results for companies. In any case, this is a multidisciplinary gap involving design, technology and linguistics with a lot of market potential.
Next steps
Voice Accent was a theoretical project that revealed great market potential. The next steps would be, together with a developer and a quality analyst, to develop a prototype with real interactions and machine learning, using current technology . In this way, it would be possible to test the accuracy of artificial intelligence and measure the costs of deploying them as real virtual assistants.