


O Voice Accent é um projeto acadêmico desenvolvido a partir de pesquisa de pós-graduação que emprega interfaces de voz (VUI), inteligência artificial e aprendizado de máquina para criar uma interface capaz de transitar entre dois idiomas ou regionalismos semelhantes, sem a necessidade de configurações adicionais por meio de um sistema de voz.


01 / SUMÁRIO
02 / Processo
03 / Entendendo o problema
04 / Fala e sotaque
05 / Tradução via fonemas
06 / Árvore de decisão
07 / Aprendizado
02 / PROCESSO
empatizar
>
>
>
pesquisa
ideação
protótipo
EMPATIZAR
03 / ENTENDENDO O PROBLEMA
O projeto Voice Accent nasceu da observação de que as assistentes virtuais de comando de voz atuais no mercado não entendem as diferenças entre idiomas diferentes, porém semelhantes, ou mesmo entre regionalismos. Um exemplo disso é que, quando configuradas em português, essas assistentes podem encontrar facilmente resultados em inglês, mas se confundem se pesquisarmos por um tópico em espanhol. Diante desse contexto, é possível criar uma experiência de voz que não exija uma interface gráfica para ajustes? Como esse comportamento afeta o uso de dispositivos de voz por pessoas com sotaque, especialmente estrangeiros que estão aprendendo um novo idioma? A inteligência artificial poderia ajudar nesse processo?
As interfaces de voz (VUI) fazem parte do grupo de interfaces naturais, ou seja, interfaces que funcionam de forma tão discreta e natural que nem percebemos que elas estão lá. A fala é natural para os seres humanos e, desde que eles não tenham deficiências cognitivas ou auditivas e falem um idioma em comum, ela também é nosso principal meio de comunicação.
Em 2023, uma pesquisa da Fundação Getúlio Vargas (FGV) revelou que 67% das pessoas no Brasil usam interfaces de voz em suas vidas diárias. Esse número certamente inclui estrangeiros e pessoas com sotaques diferentes. No entanto, essas interfaces são geralmente programadas por pessoas da região sudeste do Brasil, especialmente de São Paulo, o que acaba gerando um sotaque padrão. Como resultado, pessoas que falam de forma diferente relatam dificuldades em usar esse tipo de tecnologia, o que leva à frustração e à desistência.
04 / FALA E SOTAQUE
De acordo com a Interaction Design Foundation, as interfaces de voz são aquelas que permitem que o usuário interaja com um sistema por meio de comandos falados. As assistentes virtuais baseadas em inteligência artificial são exemplos de interfaces de voz. Este projeto é um esforço para entender o impacto que usuários bilíngues que vivem em países com idiomas diferentes dos de origem têm na interação com assistentes virtuais de voz baseadas em inteligência artificial, pois sabemos que o sotaque influencia a experiência.
O nicho utilizado para o público-alvo é formado principalmente por estrangeiros oriundos de países hispânicos que vivem no Brasil e são bilíngues entre o português brasileiro e o espanhol latino.
Interfaces de voz e discriminação: como a maneira como falamos interfere na experiência
É importante combater o preconceito linguístico, que nada mais é do que a tendência de ignorar um modo de falar. Para isso, precisei entender a diferença entre a norma culta e a norma padrão dos idiomas: a norma culta está ligada ao uso cotidiano da língua, variando conforme o grau de instrução e origem do falante. A norma padrão, por outro lado, é o acordo ortográfico-gramatical do próprio idioma. Já a variação linguística ocorre devido à influência da cultura e do contexto social, razão pela qual o português falado no Brasil é diferente do português falado em Portugal, por exemplo.
É comum que os idiomas apresentem variações linguísticas, como sotaques e maneirismos dependendo da região, da origem ou até mesmo da classe social dos falantes. E essa situação se torna ainda mais complexa quando acrescentamos diferentes idiomas de mesma origem, como as línguas latinas.
Esta introdução à linguística contextualiza o uso de interfaces de voz. A origem do fato de as assistentes virtuais não compreenderem determinados padrões de fala, está no banco de dados usados para treinar a inteligência artificial desses sistemas. Considera-se que há um viés nos dados que faz com que os computadores apresentem filtros estatísticos em seus resultados, de modo que o desempenho é afetado por bancos de dados "higienizados e homogêneos" que afetam o aprendizado de máquina. Esse resultado não é feito deliberadamente por designers e desenvolvedores, mas as decisões tomadas durante a fase de programação das interfaces de voz acabam influenciando o seu comportamento. Uma das maneiras de atenuar esse problema é usar redes neurais para identificar parâmetros de linguagem, embora mesmo assim não seja possível eliminar totalmente o viés.
Interfaces português-espanhol


Dado o contexto mencionado nos parágrafos anteriores, foquei o produto no nicho espanhol-português. Nas relações que ocorrem entre esses idiomas, é muito comum encontrar interpretações errôneas tanto por parte dos falantes de português quanto dos falantes de espanhol, devido à proximidade entre as duas línguas. Obviamente, isso também se reflete nas interfaces de voz. Para comprovar essa hipótese, lancei uma pesquisa on-line nas redes sociais com pessoas de países de língua espanhola, residentes no Brasil e fluentes em português, que também têm famílias bilíngues e utilizam interfaces de voz configuradas em português no seu dia a dia. A pesquisa revelou que:
IDEAÇÃO
05 / TRADUÇÕES VIA FONEMAS: UM ESTUDO USANDO INTELIGÊNCIA ARTIFICIAL E REDES NEURAIS
Como uma ideia para reduzir a margem de erro dos assistentes virtuais para usuários bilíngues de idiomas próximos (ou mesmo de sotaques diferentes dentro do mesmo idioma), um estudo publicado pela Cornell University em 2019 propôs modificar a inteligência artificial dos VUIs para que elas possam identificar fonemas em vez de palavras completas e aprender variações linguísticas por meio de redes neurais.
As redes neurais são sistemas de computador que refletem o comportamento do cérebro humano, permitindo que os programas reconheçam padrões e resolvam problemas por meio da inteligência artificial. Elas dependem de dados de treinamento que são usados para aprendizado de máquina e para melhorar a precisão do software ao longo do tempo.
Um método comum de criar assistentes virtuais é confiar em um grande léxico que contém pronúncias de palavras. Entretanto, esse léxico é criado manualmente pelos desenvolvedores e designers, o que limita a variedade de vocabulário. Uma possível solução para esse problema é permitir que o software aprenda fonemas e expanda automaticamente os bancos de dados sem a necessidade de uma atualização manual.
As assistentes virtuais surgiram com um grande léxico em inglês, que foi gradualmente expandido para outros idiomas. A maioria dos fonemas, cerca de 90,8%, é exclusiva de um mesmo grupo, mas possui inúmeras variações e representações que são utilizadas na construção de interfaces de voz bilíngues, pois isso evita que as inteligências artificiais cometam erros ao se depararem com palavras semelhantes em idiomas diferentes. Dessa forma, treinamos o software com referências cruzadas e criamos bancos de dados que podem ser usados para processar sequências de fonemas de qualquer tamanho. Assim, o sistema pode identificar o idioma de destino comparando os sons em seus bancos de dados sem que o usuário precise configurar manualmente sua assistente virtual, o que tornaria a interação bilíngue fluida e mais próxima da conversação humana.
Para chegar às soluções propostas na próxima seção, foi utilizada a técnica do double diamond.
A primeira etapa foi identificar o problema a ser resolvido: "como o sotaque influencia a interação com uma interface de voz", identificar o público-alvo e entender suas necessidades. Os insights obtidos mostraram que a inteligência artificial dos assistentes virtuais influencia a interação.
O mercado precisa se concentrar no algoritmo de aprendizado de máquina e em como ele processa sons e palavras. Analisei técnicas e soluções para o problema proposto, chegando à conclusão de que a interação ruim com interfaces de voz não é apenas um problema de design, mas também um problema de desenvolvimento e engenharia.
Por fim, os resultados serão uma árvore de decisão e recomendações para o desenvolvimento de uma interface de voz ideal, capaz de fazer a transição natural entre idiomas diferentes (mas semelhantes).
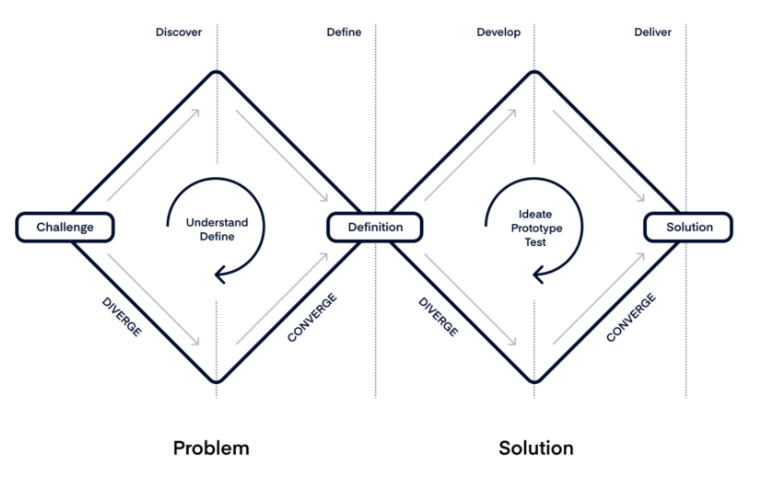
Double-diamond. Fonte: Product Board.


Raul Gonzáles
Idade: 25 anos - escolaridade: diploma universitário
"Tenho que repetir minhas palavras. A assistente simplesmente não entende o meu sotaque, pois está configurado em português."
Biografia: Hispânico que mora no Brasil há pouco tempo, ele usa assistentes de voz virtuais configuradas em português para se familiarizar mais com a língua. Ele usa seu tempo de trabalho para praticar a conversação com seus colegas brasileiros. Frustração: Ele ainda não domina muito bem o português e precisa melhorar sua fluência. Usuário digitalizado, acostumado com a tecnologia.


Mariela Aguirre
Idade: 40 anos - escolaridade: ensino médio
"Não foi compreendida porque tenho sotaque, portanto, não conclui a tarefa indicada."
Biografia: Hispânica que vive no Brasil há alguns anos, mas ainda tem muita dificuldade com os sons nasalizados típicos da língua portuguesa. Casada com um brasileiro e mãe de um filho, vive em uma família bilíngue espanhol-português porque quer que a criança cresça envolvida com as culturas de ambos os pais. Frustração: Ela tem dificuldade com fonemas típicos do português que não existem no espanhol. A usuária utiliza a tecnologia para pequenas atividades cotidianas. Ela não está interessada nas últimas inovações do mercado, mas em produtos que possam ajudá-la a resolver seus problemas.
SOLUÇÃO
06 / ÁRVORE DE DECISÃO
As interfaces de voz são prototipadas usando fluxogramas e árvores de decisão, que, no contexto do design de interfaces, são usados como sinônimos. Uma árvore de decisão é um mapa dos possíveis resultados de uma interação com base em escolhas. Geralmente, elas começam em um único ponto que se divide em diferentes caminhos.
Quando o usuário inicia uma interação com uma interface de voz, a interação geralmente começa em um campo aberto, ou seja, o usuário pode começar como quiser. Um exemplo disso são os bate-papos de autoatendimento, que começam com a pergunta aberta "O que posso fazer por você?" e o usuário responde à sua maneira. Os cenários são compreendidos pela interface por meio de palavras-chave que funcionam como marcadores e começam a orientar a conversa.
As palavras-chave no design desse sistema incluem falsos cognatos português-espanhol, fonemas compostos por LL, CH, J, RR, R, Ñ, NH e X e sons nasalizados representados pelo acento ~.
Em seguida, uma árvore de decisão simplificada é apresentada para ilustrar o projeto de uma interface de voz bilíngue em português e espanhol, considerando um método de inteligência artificial que não apenas entende palavras inteiras, mas também fonemas.

PESQUISA
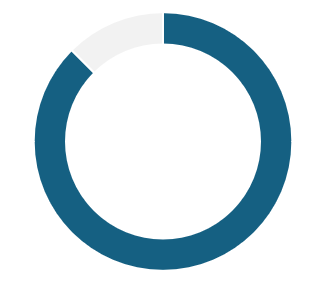
62.5% não usam
interfaces de voz
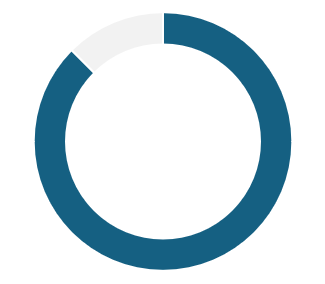
87.5% vivem em famílias
bilíngues
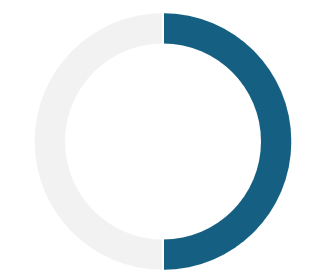
50% que têm dificuldades quando utilizam interfaces de voz configuradas em português
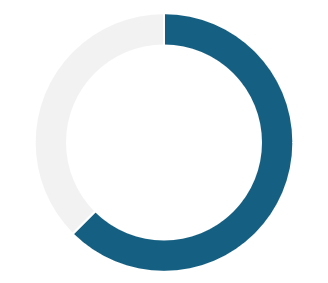
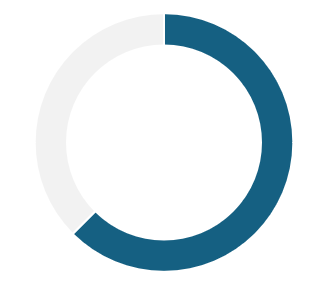
Usuários com sotaque hispânico também mencionaram que precisam repetir comandos mais de uma vez para assistentes virtuais configuradas em português porque elas não entendem as palavras ou o contexto da fala e, como resultado, não agem como esperado. A péssima experiência faz com que muitas pessoas desistam de usar esse tipo de interface.
Também pesquisei como a inteligência artificial das interfaces de voz aprende novas palavras. Atualmente, a maioria tem bancos de dados que são alimentados com palavras completas, o que dificulta a compreensão da máquina porque ela espera por determinadas sequências de sons.
Quando o problema dos sotaques nas interfaces de voz é abordado explorando o aprendizado de máquina por meio de redes neurais e fonemas, nota-se que as máquinas se tornam mais assertivas.
A gramática gerativa é uma teoria que afirma que a gramática se baseia em regras que dizem como criar frases em um idioma.
As redes residuais profundas são um tipo de rede neural especializada que ajuda a inteligência artificial a lidar com modelos complexos de aprendizado de máquina.
Os mecanismos de atenção são uma forma de representar vetores em modelos de aprendizado de máquina, em que é possível ler cada parte do vetor de informações de forma independente.






Como mencionado anteriormente, o público-alvo desse projeto são os estrangeiros, especialmente os hispânicos, que têm dificuldade em utilizar interfaces de voz configuradas em português. A partir do estudo desse público-alvo, foram criadas as seguintes protopersonas:
Árvore de decisão simplificada. Clique para expandir a imagem. (em inglês)
Conforme mencionado ao longo deste trabalho, projetar uma interface de voz capaz de compreender usuários bilíngues fora de seus idiomas nativos é um desafio tanto para o design quanto para a tecnologia. O trabalho do designer de experiência do usuário é sempre pensar na melhor experiência e na solução de problemas, mas também precisamos lidar com limitações técnicas/tecnológicas. No estudo de caso deste projeto, a limitação está ligada aos métodos de inteligência artificial usados atualmente nas assistentes virtuais. Atualmente, essas assistentes não têm memória e não conseguem entender o contexto de uma fala, resultando em um fim forçado da interação quando elas não compreendem os comandos e gerando frustração no usuário. Espera-se que, em um futuro próximo, os métodos de inteligência artificial e aprendizado de máquina baseado em fonemas sejam aprimorados e se tornem mais populares, resultando em interfaces mais precisas que ofereçam mais liberdade para decisões de design.
RESULTADOS
07 / APRENDIZADO
As assistentes virtuais baseadas em comandos de voz e inteligência artificial são tipos de interfaces de voz que estão se tornando cada vez mais populares entre os usuários. Essas interfaces nasceram em inglês e foram gradualmente traduzidas para muitos outros idiomas. No entanto, as gerações atuais ainda não são capazes de atuar no modo bilíngue ou mesmo no modo monolíngue quando o usuário não é um falante nativo do idioma configurado ou usa muitos regionalismos.
Portanto, para que uma interface de voz e uma assistente virtual se tornem mais acessíveis à diferentes tipos de fala, é necessário que os designers estudem as diferentes formas de falar dos usuários, ao mesmo tempo em que os desenvolvedores se preocupam em utilizar tecnologias de ponta capazes de aprender palavras por fonemas.
É uma grande oportunidade de mercado projetar interfaces como essa, pois muitos usuários reclamam de não serem atendidos adequadamente, a ponto de abandonarem o uso de assistentes de voz virtuais. Um designer deve estar sempre atento às necessidades e aos problemas dos usuários e projetar soluções que agradem ao seu público-alvo e tragam bons resultados para as empresas. De qualquer forma, essa é uma lacuna multidisciplinar que envolve design, tecnologia e linguística com muito potencial de mercado.
Próximos passos
O Voice Accent foi um projeto teórico que revelou um grande potencial de mercado. As próximas etapas seriam, juntamente com um desenvolvedor e um analista de qualidade, desenvolver um protótipo com interações reais e aprendizado de máquina. Dessa forma, seria possível testar a precisão da inteligência artificial e medir os custos de sua implantação como assistentes virtuais reais.